eXPaNd
The Expand Parallel File System
The Expand Parallel File System
Motivation
The main motivation of Expand is to build a parallel file system for heterogeneous general purpose distributed
environments. To satisfy this goal, we use Network File System (NFS).
NFS supports the NFS protocol, a set of remote procedure call (RPC) that provides the
means for clients to perform operations on a remote file server. NFS protocol is operating system
independent. Developed originally
for being used in networks of UNIX systems, it is widely available today in many
systems, as LINUX or Windows 2000, two operating systems very frequently used in clusters.
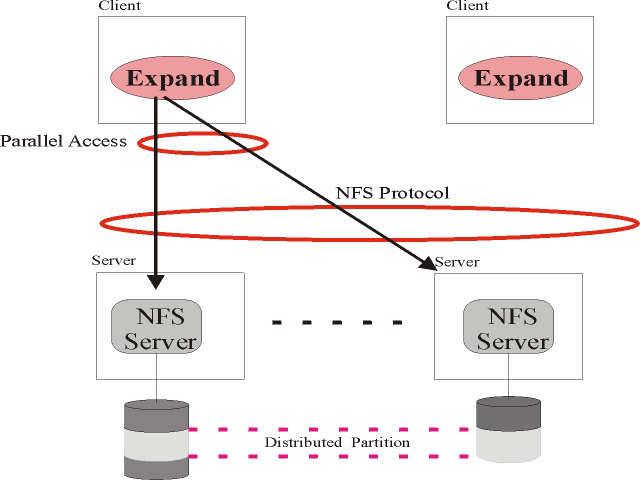
Figure 1 shows the architecture of Expand. This architecture shows how multiple NFS servers can be used as a
single file system. File data are declustered by Expand among all NFS servers, using blocks of different sizes as stripping
unit.
Processes in clients use an Expand library to access an Expand distributed
partition.
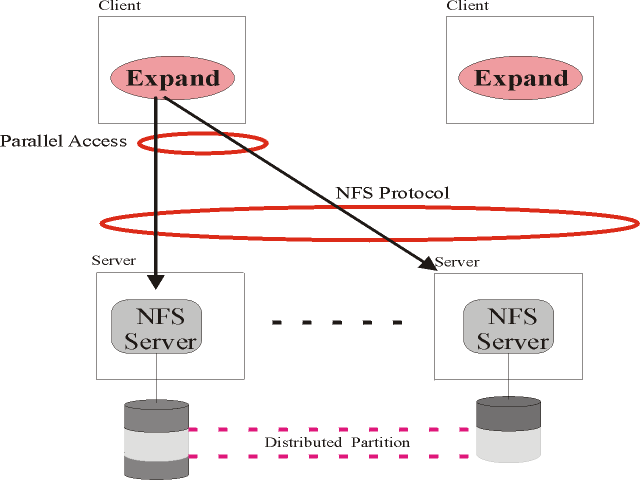
Fig 1. Architecture of Expand
Using the former approach offers the following advantages:
No changes to the NFS server are required to run Expand. All aspects of Expand operations are implemented on the clients. In this way, we can use several servers with different operating system to build a distributed partition. Furthermore, declustered partitions can coexist with NFS traditional partitions without problems.
Expand is independent of the operating system used in the client. All operations are implemented using RPC and NFS protocol. Expand is available for Linux and Windows plataforms. Furthermore, we provide an universal Java client.
The parallel file system construction is greatly simplified, because all operations are implemented on the clients. This approach is completely different to that used in many current parallel file system, that implement both client and server sides.
It allows parallel access to both data of different files and data of the same file, reducing the bottleneck that represents the traditional distributed file systems.
It allows the using of servers with different architectures and operating systems, because the NFS protocol hides those differences. Because of this feature, Expand is very suitable for heterogenous systems, as cluster of workstations.
NFS servers use caching, increasing int this way the performance.
It simplifies the configuration, because NFS is very
familiar to users. Server only
need to export the appropriate directories and clients only need a little configuration file that explain the distributed
partition.
Design
Expand provides high performance I/O exploiting parallel accesses to files
stripped among several NFS servers. Expand is designed as a client-server system
with multiple NFS servers, with each Expand file striped across some of the NFS
servers. All operations in Expand clients are based on RPCs and NFS protocol.
The first prototype of Expand is a user-level implementation, through a library
that must be linked with the applications. Expand provides a global name space
in all cluster.
Next sections describe data distribution, file structure, naming, metadata
management, and parallel access to files in Expand.
Data Distribution
To provide large storage capacity and to enhance flexibility, Expand combines
several NFS servers to provide a generic stripped partition which allows to
create several types of file systems on any kind of parallel I/O system.
Each server exports one o more directories that are combined to build a
distributed partition. All files in the system are declustered across all NFS
servers to facilitate parallel access, with each server storing conceptually a
subfile of the parallel file.
A design goal, no implemented in the current prototype, is to allow that a
partition in Expand can be expanded adding more servers to an existing
distributed partition.This feature increases the scalability of the system and
it also allows to increase the size of partitions. When new servers are added to
an existent partition, the partition must be rebuilt to accommodate all files.
Conceptually, this rebuilding will be made using the following idea:
rebuild_partition(old_partition,
new_partition) {
for each file in
old_partition {
copy the file
into the new partition
unlink the
file in old_partition
}
}
In this algorithm, when a file is copied into the new partition, the new file is
declusterd across all NFS server of the new partition. To implement this
expansion, algorithms must be designed to allow a redistribution of data without
integrally copying files.
The Structure of Expand Files
A file in Expand consists in several subfiles, one for each NFS partition.
All subfiles are fully transparent to the Expand users. Expand hides this
subfiles, offering to the clients a traditional view of the files. This idea is
similar to the used in PVFS.
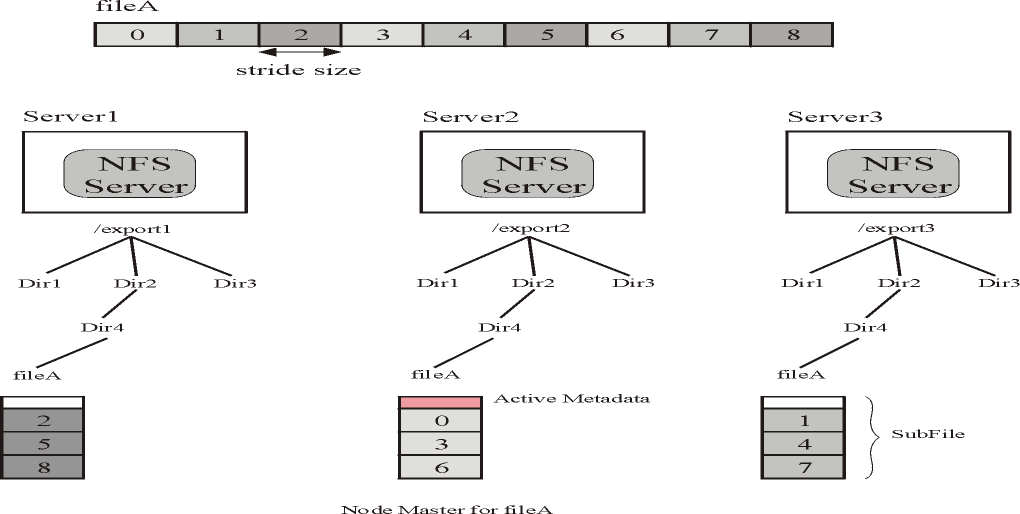
On a distributed partition, the user can create in the current prototype stripped files with cyclic layout. In these files, blocks are distributed across
the partition following a round-robin pattern. This structure is shown in Figure
2. Each subfile of a Expand file as a small header at the beginning of the
subfile. This header stores the file's metadata. This metadata includes the
following information:
All subfiles has a header for metadata, although only one node, called
master node (described below) stores the current metadata. The master node can
be different from the base node.
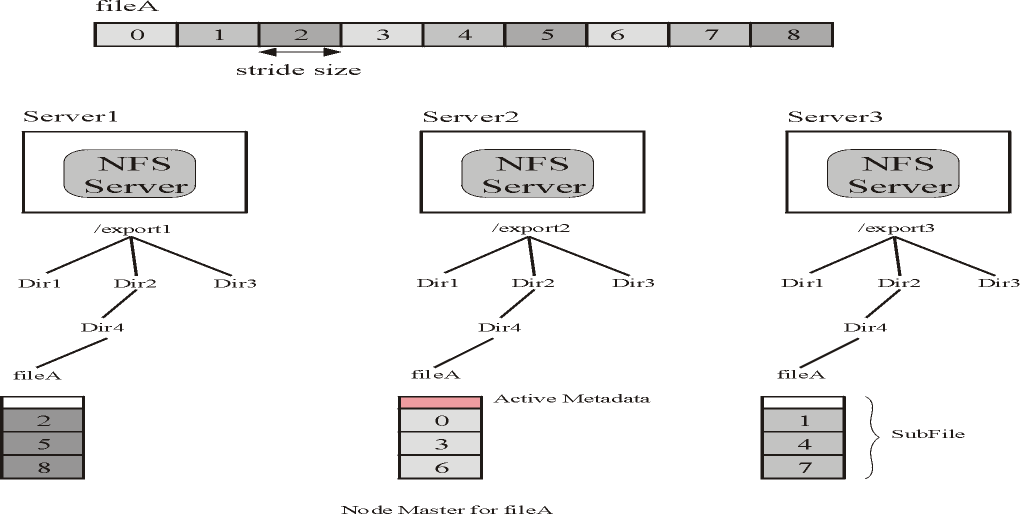
Fig2. Expand file with cyclic layout
Naming and metadata management
To simplify the naming process and reduce potential bottlenecks, Expand does not use any metadata manager, as the used in PVFS
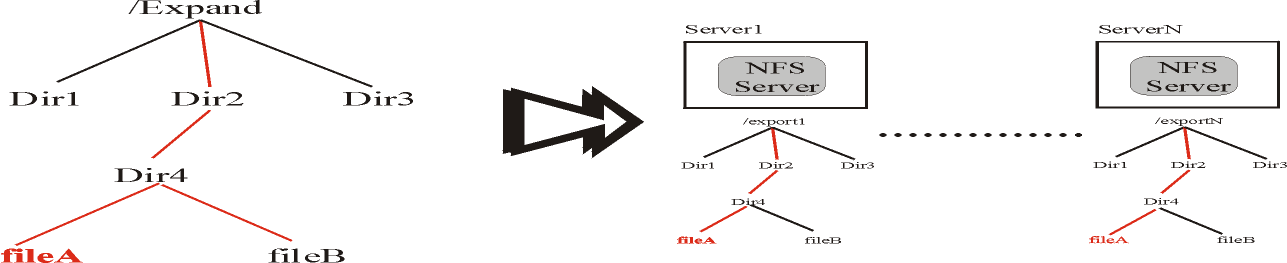
. Figure 3 shows how directory mapping is made in Expand. The Expand tree directory is replicated in all NFS
servers. In this way, we can use the lookup operation of NFS without any change to access to all subfiles of a file. This
feature also allows access to fault tolerance files when a server node fails.
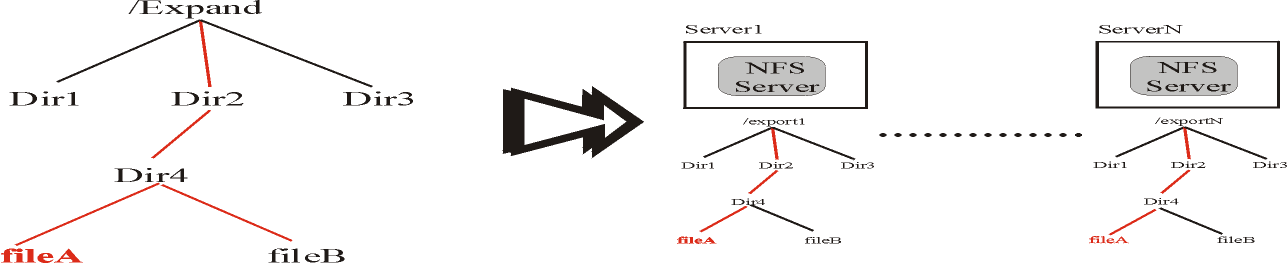
Fig3. Directory Mapping
The metadata of a file resides in the header of a subfile stored
in a NFS server. This NFS server is the master node of the file, similar to the
mechanism used in the Vesta Parallel File System. To obtain the master node of a file, the
file name is hashed into the number of node:
hash(namefile) = NFS serverI
The use of this simple approach offers a good distribution of masters.
Initially the base node for a file agrees with the master node. The use of this simple scheme allows to distribute the master
nodes and the blocks between all NFS servers, balancing the use of all NFS servers
and, hence, the I/O load.
Because the determination of the master node is based on the file name, when a user renames a file, the master node for this file is
changed. The algorithm used in Expand to rename a file is the following:
rename(oldname, newname) {
oldmaster = hash(oldname)
newmaster = hash(newname)
move the metadata from oldmaster to newmaster
}
This process is shown in Figure 4. Moving the metadata is the only operation needed to maintain the coherence of the base
node system for all the Expand files.
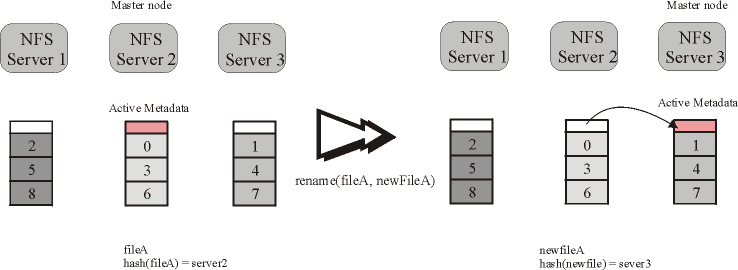
Fig 4. Renaming a file
Parallel access
NFS clients use filehandle to access the files. A NFS filehandle is an opaque reference to a file or directory that is
independent of the filenane. All NFS operations use a filehandle to identify the file or directory which the operation applies
to. Only the server can interpret the data contained within the filehandle. Expand
uses a virtual filehandle, that is defined as the union of all filehandleI, where
filehandleI is the filehandle used for the NFS server I to reference the subfile
I belonging to the Expand file. The
virtual filehandle is the reference used in Expand to reference all operations. When Expand needs to access to a
subfile, it uses
the appropriated filehandle. Because filehandles are opaque to clients, Expand can use different
NFS implementations for the same distributed partition.
To enhance I/O, user requests are split by the Expand library into parallel subrequests sent to the involved NFS
servers. When a
request involves k NFS servers, Expand issues k requests in parallel to the NFS
servers, using threads to parallelize the operations. The same criteria is used in all Expand
operations. A parallel operation to k servers is divided in k
individual
operations that use RPC and the NFS protocol to access the corresponding
subfile.
User Interface
Expand offers two different interfaces. The first interface is based on POSIX system
call. This interface, however, is not
appropriate for parallel applications using strided patterns with small access size. Parallel applications can also used Expand with
MPI-IO. Expand have been
integrated inside ROMIO
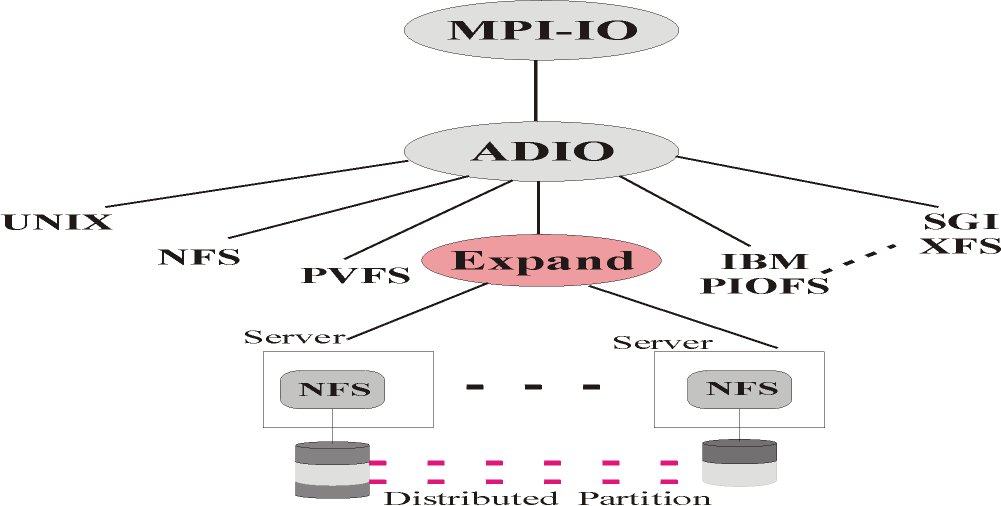
and can be used with MPICH
(see Figure 5). Portability in ROMIO is achieved using an abstract-device interface for
IO (ADIO).
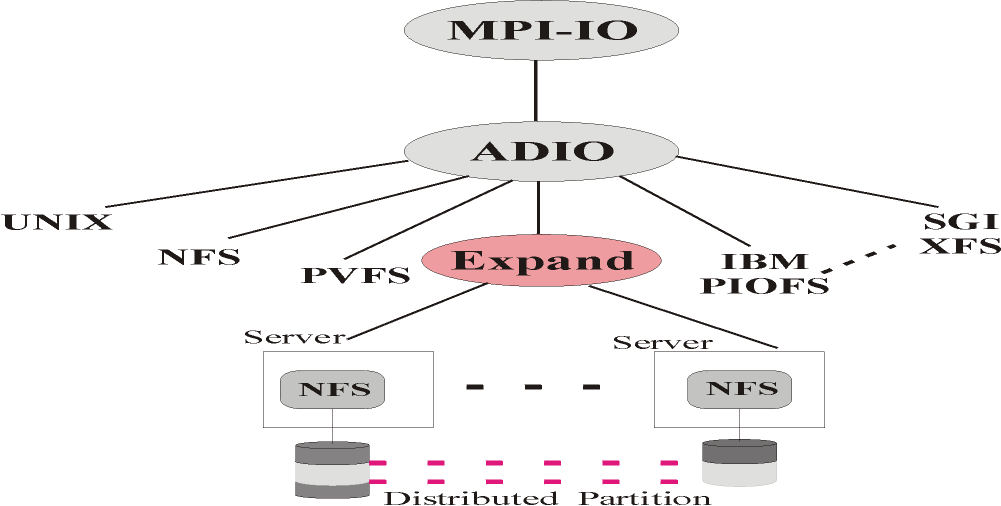
Fig 5. Expand inside ROMIO
ADIO
is a mechanism specifically designed for implementing parallel-I/O APIs portably on multiple file
systems. ADIO consists of a small set of basic functions for parallel I/O. The ROMIO implementation of
MPI-IO use the ADIO to achieve portability. The ADIO interface implemented for
Expand includes:
Open a file. All opens are considered to be collective operations.
Close a file. Close operation is also a collective operation.
Contiguous reads and writes. ADIO provides separate soutines for contiguous and noncontiguous access.
Noncontiguous reads and writes. Parallel applications often need to read or write data that is located in a noncontiguous fashion in files and even in memory. ADIO provides routines for specifying noncontiguous accesses with a single call.
Nonblocking reads and writes}. ADIO provides nonblocking versions of all read and write calls.
Collective reads and writes. A collective routine must be called by all processes in the group that opened the file.
Seek. This function can be used to change the position of the individual file pointer.
Test and wait. These operations are used ti test the completion of nonblocking operations.
File Control. This operation is used to set or get information about an open file.
Miscellaneous. Other operations included in ADIO provides routines for deleting files, resizing files, flushing cached data to disks, and initializing and terminating ADIO.
Configuration
To configure Expand, the user must to specify in a configuration file the Expand partition. An example of configuration file is the following:
/xpn1
8 4
server1 /export/home1
server2 /export/home2
server3 /export/home3
server4 /home
/xpn2 4 2
server1 /users
server3 /export/home/users
This file defines two expand partition. The first partition uses 4 servers (server1, server2, server3, and server4) and it uses by default a stripping unit of 8 KB. The second partition uses 2 servers and it uses a stripping unit of 4 KB. The path /xpn1 is the root path for the first partition, and /xpn2 is the root path for the second partition. So, the expand file /xpn1/dir/data.txt is mapped in the following subflies:
/export/home1/dir/data.txt in server1
/export/home2/dir/data.txt in server2
/export/home3/dir/data.txt in server3
/home/dir/data.txt in server4
Evaluation
In this section we show the results obtained in Expand with MPI-IO using two workloads:
Strided accesses.
An out-core matrix multiplication.
In the strided access tests, multiple noncontiguous regions of the
data file were simultaneously accessed by each process. We used a
file of 100 MB and different access size (from 128 bytes to 4MB).
The out-of-core matrix multiplication assumes a NxN matrix. This implementation doesn't do anything fancy with memory management
and simply assumes that each processor can hold 3N elements (each element is the type
double) in core at one time: 2N elements for
matrices A and B, and N elements for matrix C. The multiplication process is shown
in Figure 6. This is the algorithm using
MPI-IO. All matrix are stored in disks is row order.
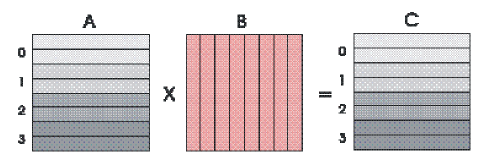
Fig 6. Matrix Multiplication
The platform used in the evaluation was a cluster with 8 Pentium III
biprocessors, each one with 1GB of main memory, connected
through a Fast Ethernet, and executing Linux operating system (kernel 2.4.5). All experiments have been executed on Expand
(XPN
in figures) and PVFS using MPI-IO as interface. For both parallel file system, we have used 8
I/O servers. The block size used in all files, both in Expand as PVFS
tests, has been 8 KB. All clients have been executed in the 8 machines, i.e:
all machines in the cluster have been used as server and clients.
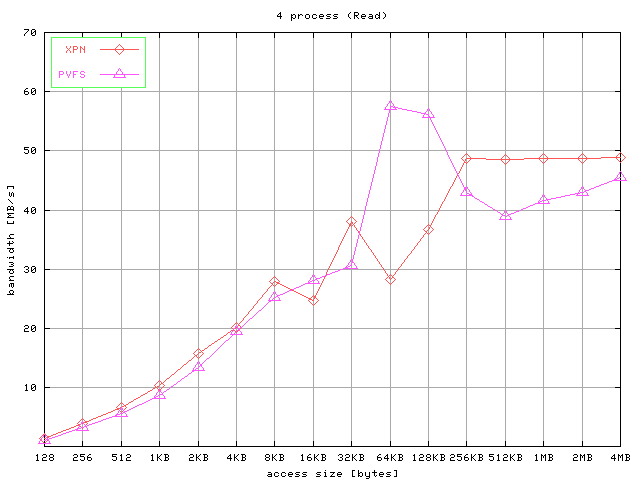
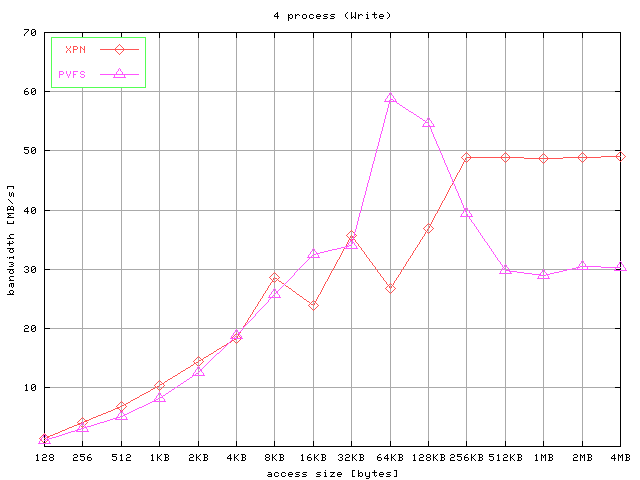
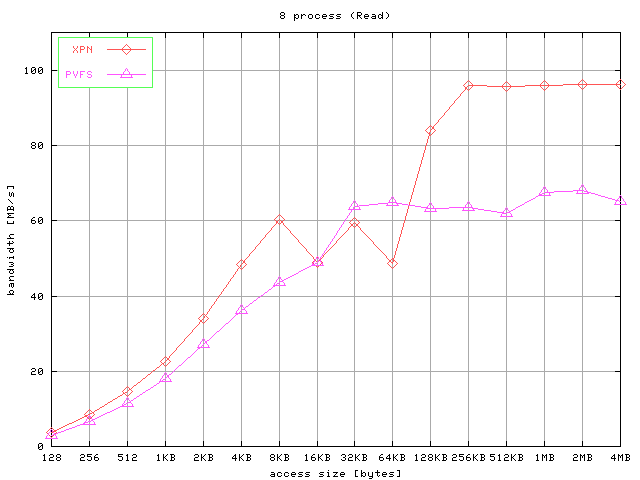
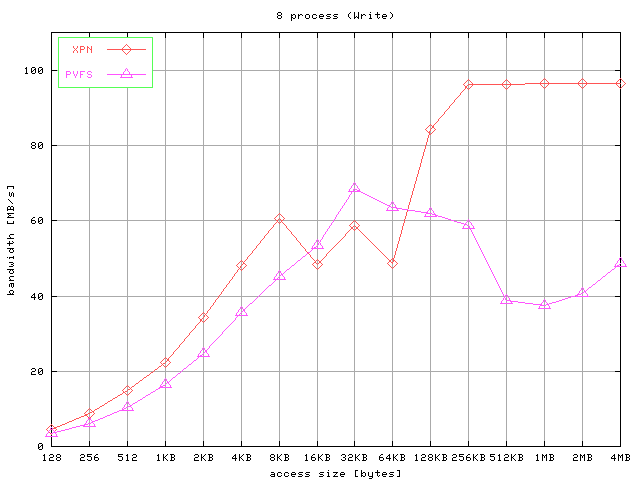
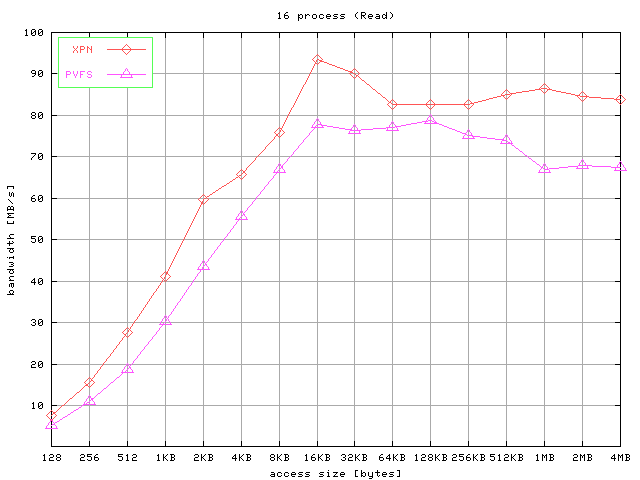
The results for strided accesses are shown in Figure 7. Graphics show the aggregated bandwidth obtained for
write operations and read operations for 4, 8, and 16 processes and different access
size.
 |
 |
 |
 |
 |
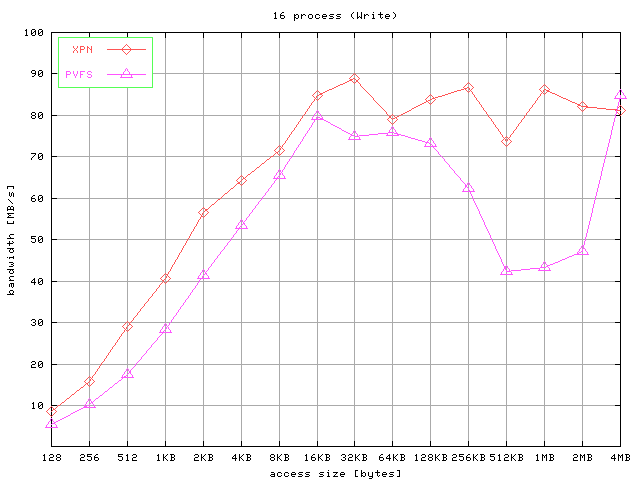 |
Fig 7. Results for strided access
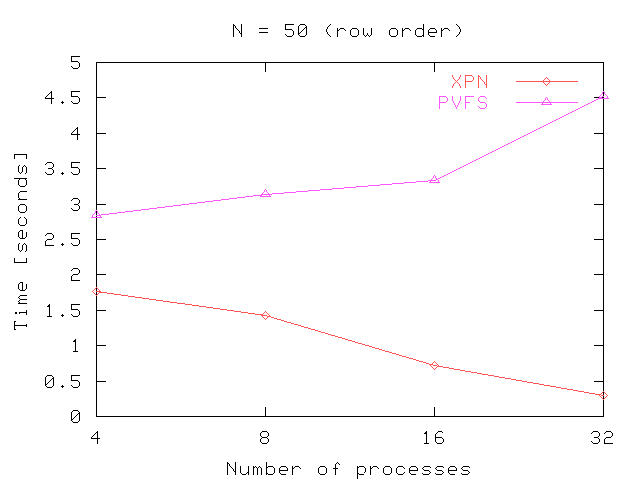
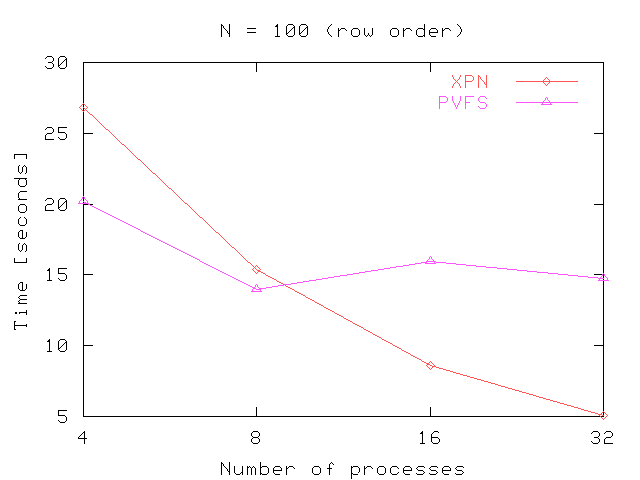
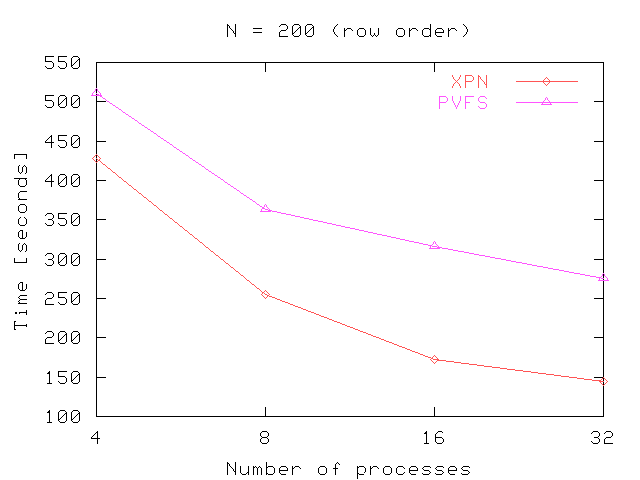
Figure 8 shows the performance obtained in the out-of-core matrix multiplication. These figures shown the time in seconds needed to multiply matrix of different sizes using several processes (4, 8, 16 and 32 processes). In general, the performance obtained in Expand scale better with the number of processes. As we can see in the figures, the time needed is increased considerably when N increase, because all matrix are stored in row order. The algorithm used read, however, the Matrix B in column order. This provokes many internal seek operations to read the whole matrix.
 |
 |
 |
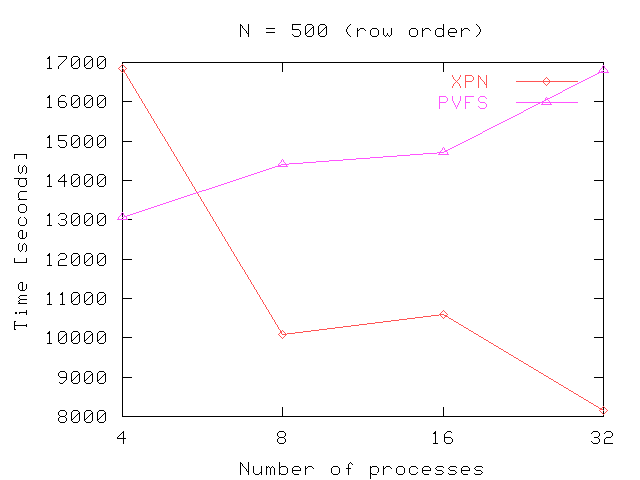 |
Fig 8. Results for out-of-core matrix multiplication
Other articles using Expand






